

简介:在搜索推荐场景中,GMV是一个重要的业务指标。 点击率预测模型(pCTR)和转化率预测模型(pCVR)是整个算法应用场景的重要组成部分。 它们与GMV的关系可以用一个方程大致表示:GMV = 曝光度\乘以pCTR\乘以pCVR\乘以价格。 因此,pCTR和pCVR预测越准确,能够创造的价值就越大; 从模型训练的角度来看,曝光\rightarrow点击\rightarrow购买转化的漏斗状路径中,不同阶段样本量相差几个数量级,不同阶段能够得到的特征也不同。 同时,当训练样本选择不当时,会出现离线训练、离线训练的情况。 关于推理阶段样本空间不一致的问题酷24体育,,本文结合阿里巴巴发表的三篇论文,看看业界如何利用多任务学习、知识蒸馏等深度学习技术来解决这些问题,以及其他方面可以学到什么场景。
优势特征蒸馏在pCVR模型中的应用
本文将首先介绍背景、使用模型需要解决的三个问题,以及解决方案ESMM多任务网络、知识蒸馏技术。 主要内容基于阿里巴巴发表的三篇论文。 如果你想阅读全文,可以参考一下。 如下:
背景数据稀疏和样本选择偏差
在电商场景中,用户的行为顺序一般为:曝光\右箭头点击\右箭头购买转化。 对于这样的漏斗转换路径,样本大小会因几个数据级别而异,因此很容易遇到数据稀疏问题。 对于最下游的转化率预测,问题(数据稀疏性,DS)尤为明显。 论文1公开的数据集中,点击率(click\exposure=4\%)和转化率(conversion/click=0.5\%),样本量不足会导致模型性能较差kaiyun下载app下载安装手机版,,预测不准确pCVR在业务指标中发挥着重要作用。
另一个问题是样本选择偏差(SSB)。 很多转化率预测模型都是使用点击样本(点击后)进行训练的,即对于用户点击后的样本,根据是否购买生成训练标签(1:点击并购买,0:点击且不购买) ),在线预测工作在曝光阶段,因此存在离线样本和在线样本不一致的问题。 示意图如下图所示,很多机器学习算法的泛化性都假设数据服从独立同分布。 如果训练样本空间和测试样本空间存在较大差异ctr预估模型算法,那么在线和离线的模型性能将会有很大差异。
样本选择偏差的问题在风险信用评分模型中也很常见,但整个漏斗路径既包括用户自身的主动行为因素,也包括风险策略的被动干预因素。 在后续的思路扩展部分,详细描述一下。
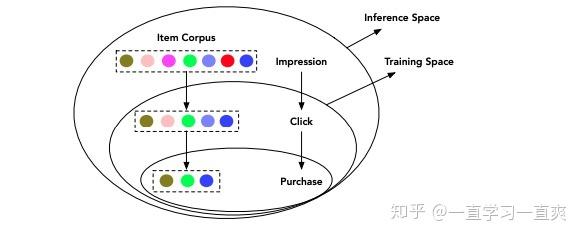
曝光和点击阶段可用的功能不一致
显然,在线预测阶段,转化率预测模型需要在产品曝光阶段开始评分(点击后的其他特征无法使用),生成排名因子,最后为用户生成推荐列表,从而确定转化速率预测 模型可以使用的特征需要与曝光阶段可以获得的特征一致。 然而,点击商品后,与购买转化强相关的行为,比如加入购物车、分享、在商品详情页停留时长、客服咨询等行为……都可以产生大量的用户行为特征。 这些特征对于预测转化具有很强的区分能力。 论文 3 将这些功能称为特权功能。 有些人在网上将它们翻译为有利的功能。 更常见的定义是:在训练阶段可以追溯到但在在线推理阶段无法获得并且对模型性能具有较高判别能力的特征。 如下图所示,展示了用户在详情页的行为以及可以获得的优势功能:

ESMM-全空间多任务学习模型ESMM网络结构
为了解决数据稀疏和样本选择偏差的问题,论文1首先提出了ESMM多任务学习框架。 在此基础上,论文2引入了更多的用户行为序列,添加了更多的任务,并提出了ESMM的增强版本。 ,下面对这两种方法进行简单介绍。
论文1由阿里妈妈在SIGIR '18:第41届国际ACM SIGIR信息检索研究与发展会议上发表。 它提出了一种多任务学习框架,根据用户的行为序列在暴露阶段(全空间)同时进行训练。 点击率预测模型(浏览后点击率,pCTR,曝光后点击行为),点击和转化预测模型(浏览后点击率和转化率,pCTCVR,曝光后点击和转化),点击转化预测模型pCVR。
将训练数据集表示为:S = \{(x_i,y_i \rightarrow z_i)\}|_{i=1}^N,其中x_i表示曝光阶段的特征向量,y_i,z_i表示点击与否,购买是否的标签,N代表暴露的样本量。 由于 y_i \rightarrow z_i 具有依赖关系ctr预估模型算法,因此只有先点击才会发生购买行为。 也就是我们常说的转化率估算模型是:
pCVR = p(z=1 | y=1, x) \\
点击率预测模型为:
pCTR = p(y=1 | x) \\
点击和转化估算模型为:
pCTCVR = p(y=1,z=1| x) \\
因此,基于依赖关系,将上述三个模型整合为一个公式:
\begin{对齐}pCTCVR &= pCTR \times pCVR \\p(y=1,z=1| x) &= p(y=1 | x) \times p(z=1 | y=1, x) \end{对齐} \\
通过上述公式,要实现使用所有样本的全空间训练,即使用所有曝光样本及其标签进行训练,损失函数中只需包含两个任务的损失:pCTR和pCTCVR。 因此,三个模型中,只有上面两个是在曝光阶段使用样本,而pCVR只是作为一个系数,一个中间变量,但这个系数也是通过网络训练得到的,只是点击后的样本并不是直接用于训练,因此ESMM的网络结构如下图所示:
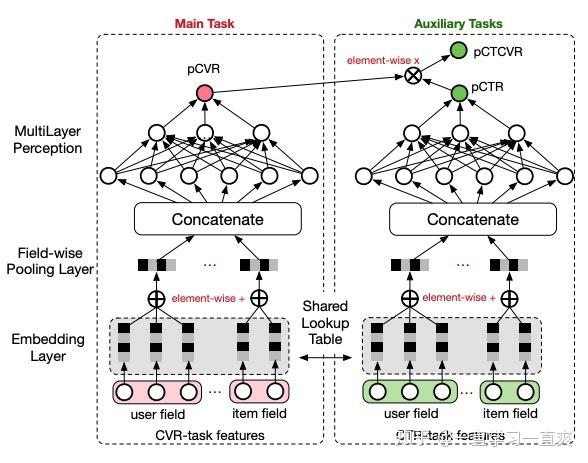
这种网络结构的特点是:
对于训练损失函数来说,就是在所有曝光样本上训练的两个辅助任务pCTR和pCTCVR的损失,不需要直接加上pCVR的损失,如下式所示:
\begin{对齐}L(\theta_{cvr}, \theta_{ctr}) &=\sum_{i=1}^N l(y_i,f(x_i;\theta_{ctr})) + \sum_{i =1}^N l(y_i\&z_i,f(x_i;f(x_i;\theta_{ctr}) \times f(x_i;\theta_{cvr}))) \end{对齐} \\
根据上述网络结构和损失函数即可训练模型。 至此就完成了ESMM的介绍。 另外,由于pCTR、pCTCVR和pCVR之间的关系可以变换如下,
\begin{对齐}p(y=1,z=1| x) &= p(y=1 | x) \times p(z=1 | y=1, x) \\\右箭头 p(z=1 | y=1, x) &= \frac{p(y=1,z=1| x)}{p(y=1 | x) }\end{对齐} \\
看来pCVR可以通过分别训练两个任务pCTR和pCTCVR直接推导出来。 然而,与ESMM网络相比,这种方法有缺点:
ESMM增强版
对于Paper 1来说,只考虑了一条比较粗的路径:曝光\rightarrow点击\rightarrow购买转化,而Paper 2中的ESMM增强版在点击和购买转化之间增加了一条新的路径,即点击后的行为进行了分解更精细(正如标题所说的Post-Click Behaviour Decomposition),希望能够使用更多额外的标签数据来再次缓解数据稀疏问题; 从接触到购买,笔者将其路径分解如下图:
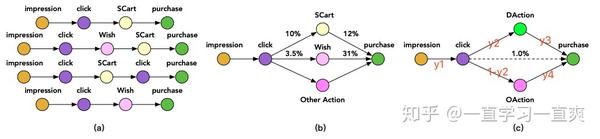
我们来看看如何利用条件概率来整合上图C中点击和购买之间更多的行为标签信息,生成更多的任务,以及哪些任务的损失项需要添加到损失函数中。 对于图中的转化路径,总共可以分为5条路径。 然而,由于单击 \rightarrow DAction 和单击 \rightarrow OAction 的概率之和为 1,因此您只需计算其中一条路径的概率。 最后,需要获得 4条路径的转移概率就足够了。 为了与论文1中的公式网格保持一致,将对原文中的公式进行一些修改。 如果需要看原文,可以参考原文Paper 2。下面的公式中,a代表是否有购买相关的动作,c代表是否有点击。 b表示是否购买转换。 根据这些模型就可以得到相应路径中转移概率计算公式之间的关系。
点击率估算 pCTR-完整样本
印象\rightarrow click,从曝光到点击的概率,即预估点击率pCTR,直接用下面的公式表示。 这里就比较简单了,没什么好说的,样张就是曝光阶段的全样:
\begin{对齐}pCTR = p(c=1|x) \overset{\Delta}{=} y_{1} \end{对齐} \\
点击和确定性转化行为转化率估算 pCTAVR-完整样本
该预测模型针对路径展示\rightarrow click \rightarrow DAction 进行建模。 在此路径中,需要单击样本才能到达 DAction。 这一步与ESMM的pCTCVR类似,只不过这里的变换指的是与购买相关的行为,比如添加到购物车等,用符号表示为pCTAVR,其计算公式为:
\begin{对齐} pCTAVR &= p(a=1,c=1 | x) \\ &= p(c=1 | x ) \times p(a=1| c=1, x) \\ &= y_1 y_2 \end{对齐} \\
其中,点击 \rightarrow DAction 路径的概率为: p(a=1| c=1, x) \overset{\Delta}{=} y_{2};
转化率估算 pCVR-Click 示例
这里涉及到两条路径,点击\rightarrow DAction\rightarrowpurchase和点击\rightarrowOAction\rightarrowpurchase,所以pCVR的公式为:
\begin{对齐}pCVR &= p(b=1| c=1, x) \\&= p(b=1,a=1 | c=1, x) + p(b=1,a=0 | c=1, x) \\&= p(b=1|a=1,c=1, x)\times p(a=1|c=1,x) + p(b=1|a= 0,c=1, x)\times p(a=0|c=1,x) \\&= y_3 y_2 + y_4(1 - y_2) \end{对齐} \\
其中,DAction \rightarrow 购买路径 \overset{\Delta}{=} y_{3} 上的概率 p(b=1|a=1,c=1, x),概率 p( b=1| a=0,c=1, x) \overset{\Delta}{=} y_{4}
点击和转化率估算 pCTCVR-完整样本
对于全曝光样本上的最终pCTCVR值,即从曝光到购买的预测概率为
\begin{对齐}pCTCVR &= p(b=1|x) \\&= p(b=1|c=1, x)\times p(c=1|x) \\&= y_1\big[ y_3 y_2 + y_4(1 - y_2)\big] \\&= pCTR \times pCVR \end{对齐} \\
有了上述pCTR、pCTAVR、pCVR、pCTCVR之间的关系,以及是否有利于样本的充分暴露,我们就可以开始设计网络结构和损失函数项了。 由于上述四个模型中,仅使用了pCTR、pCTAVR、pCTCVR,当达到全样本量时,损失函数中只能包含这三项。 网络结构如下图所示:
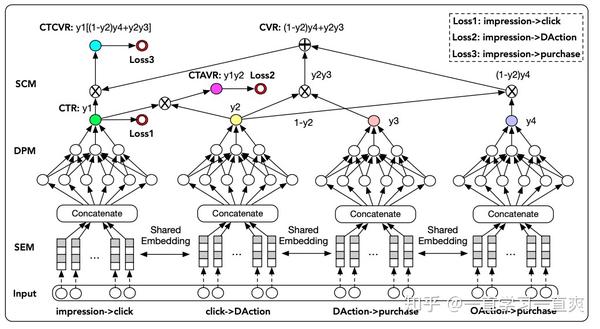
优势特征蒸馏在pCVR模型中的应用
论文1和论文2均基于用户行为路径的依赖性来设计网络结构,并充分利用曝光时刻的样本来训练多任务网络,以缓解样本选择偏差和变换数据稀疏的问题ctr预估模型算法,同时论文3采用模型蒸馏技术,利用Teacher和Student网络结构,充分利用点击后与购买行为强相关的特征,将Teacher学到的知识蒸馏到Student网络结构中,以提高Student的表现网络并在线部署学生网络模型。 此时,虽然特征是点击之前的特征,但由于Teacher所学的知识,在预测阶段的表现更好; 下图展示了模型蒸馏和优势特征蒸馏在网络架构上的异同:
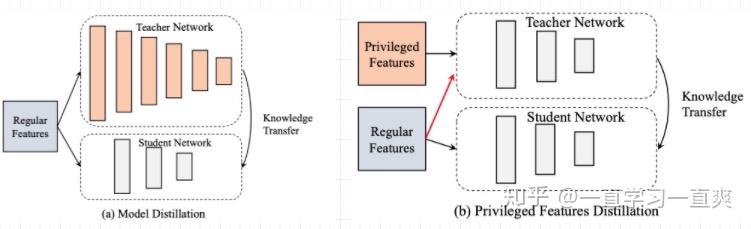
PFD的算法流程图如下:

有几点需要注意:
其他细节在此不再赘述。 有兴趣的同学可以进一步了解该模型的其他细节。
风险模型可以借鉴的地方
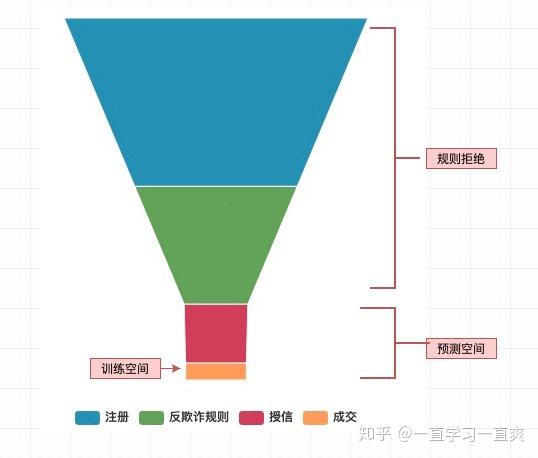
对于风险模型,用户从注册到最终成功提现也经历了一个漏斗型的转化路径,这与电商场景不同。
同名公众号也发布了相同内容:不断学习,永远快乐
2024欧洲杯 酷24体育 kaiyun下载app下载安装手机版 云开·全站appkaiyun官网




